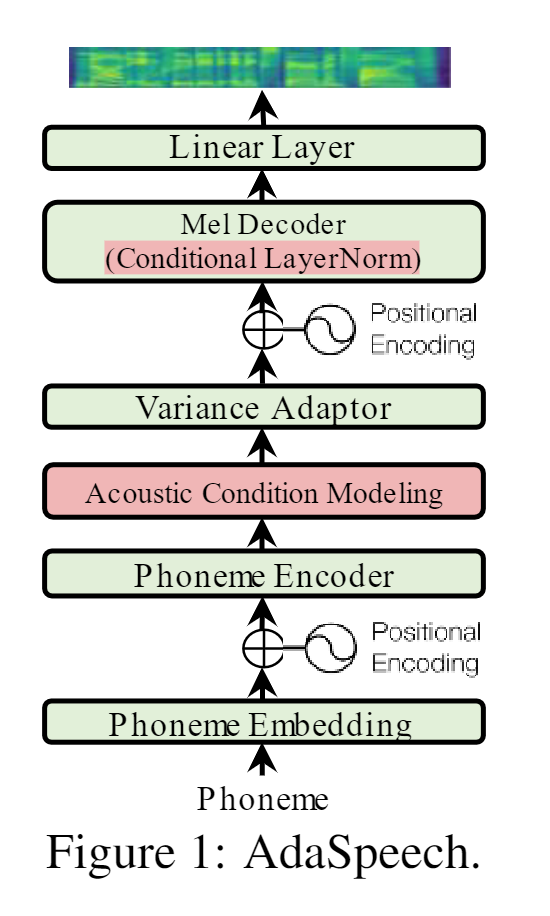
This is a unofficial PyTorch implementation of Microsoft’s text-to-speech system AdaSpeech: Adaptive Text to Speech for Custom Voice. This project is based on ming024’s implementation of FastSpeech. Feel free to use/modify the code.
Adaspeech Synthesize samples
LJSpeech
| LJ013-0238 (Ground-Truth) | LJ013-0238 (Ground-Truth mel + Vocoder ) | LJ013-0238 (Synthesized mel + Vocoder) |
|---|---|---|
Text: he was coachman to a gentleman at roehampton. one day he went into a pawnbroker's at wandsworth, and bought a pair of breeches on credit.
| LJ028-0146 (Ground-Truth) | LJ028-0146 (Ground-Truth mel + Vocoder ) | LJ028-0146 (Synthesized mel + Vocoder) |
|---|---|---|
Text: as fast as they dug the moat, the soil which they got from the cutting was made into bricks,
KSS dataset
| 3_4121 (Ground-Truth) | 3_4121 (Ground-Truth mel + Vocoder ) | 3_4121 (Synthesized mel + Vocoder) |
|---|---|---|
Text: 이달 말까지 이 쿠폰을 사용하셔야 합니다
| 4_4416 (Ground-Truth) | 4_4416 (Ground-Truth mel + Vocoder ) | 4_4416 (Synthesized mel + Vocoder) |
|---|---|---|
Text: 어떻게 하면 소비자와 생산자 둘 다 만족할 수 있을까
Discussion
In the inference step, Adaspeech’s synthesis performance was highly dependent on the reference mel.
Which means, synthesis performance is expected to increase significantly if the emotional state of the speaker and the type of sentence (question, negative, etc.) are classified and used as a reference mel.